














前回、デバッグを行いエラーが発生しました。
今回は発生したエラーの対処をしていきます!
どのようなエラーか確認
ここで改めて前回発生したエラーの画像を掲載します。
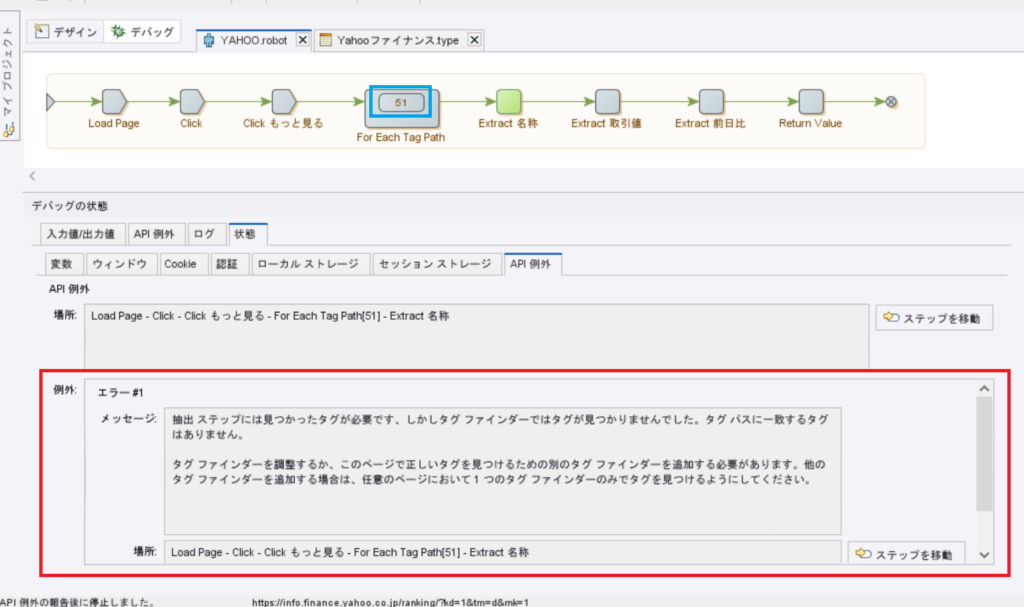
この赤枠の中のメッセージにエラーの内容が書かれているので、エラーが発生したらまずはこのメッセージを確認して、何が原因でロボットが止まってしまったのかを把握します。
今回のエラーメッセージは、「抽出ステップには見つかったタグが必要です。しかしタグファインダーではタグが見つかりませんでした。タグパスに一致するタグはありません。」というものです。
実はこのエラーメッセージはよく出てきますが、要するに「抽出したいものが見つからない」というエラーです。
どこでエラーが発生しているのかを確認
エラーメッセージを確認したら、次はどのステップでエラーが発生しているのかを確認します。
下のキャプチャの赤枠のステップが黄緑色になっているので、この名称を抽出しているステップでエラーが発生したということです。
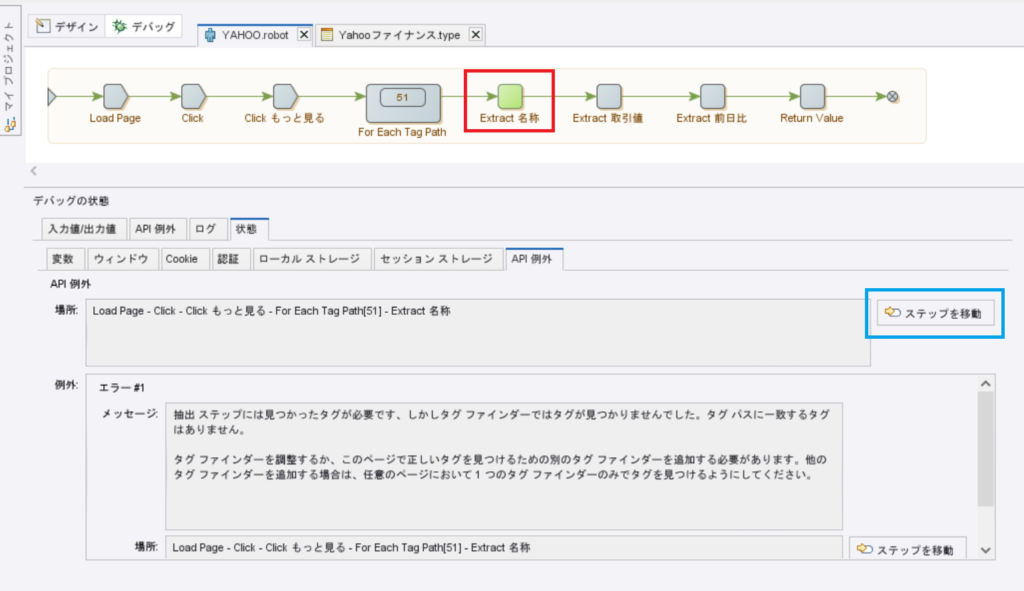
なので、このステップをこれから確認をして修正をしたいのですが、上のキャプチャの青枠の「ステップを移動」をクリックすると、デザインモードに変わり、エラーが発生したステップに移動してくれます!
すると下のキャプチャの赤枠のようにエラーが発生している状態を、BizRobo!のブラウザ上に表示をしてくれます。
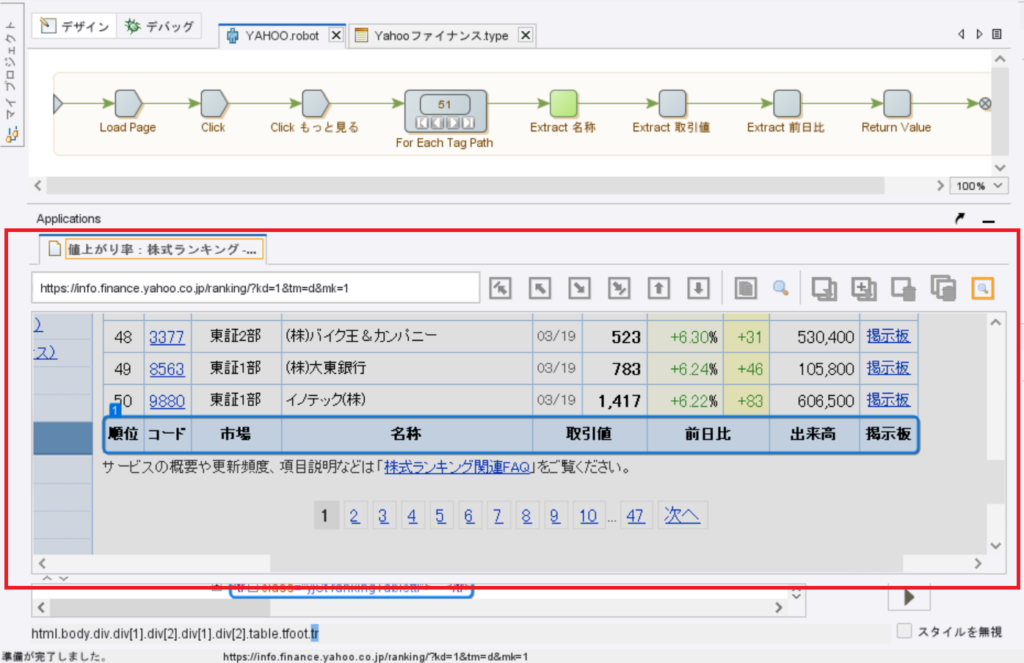
今回の場合このブラウザを見たら、なぜエラーが発生したか分かりますでしょうか?
ループの設定を変える
上記のブラウザの画面で、ループの範囲を表示している1番の青い枠はフッターの部分を囲んでしまっています。
つまりフッターの部分には、抽出してきたい名称の情報がないためエラーとなっています。
※厳密にいうとhtmlの中身が関連してくるのですが、今の段階ではこちらの認識で大丈夫です
そのため、ループの設定を変更してフッターのところまでループをしなくなれば、今回のエラーは発生しなくなります。
ループの設定を変更するため、ループのステップをクリックします。
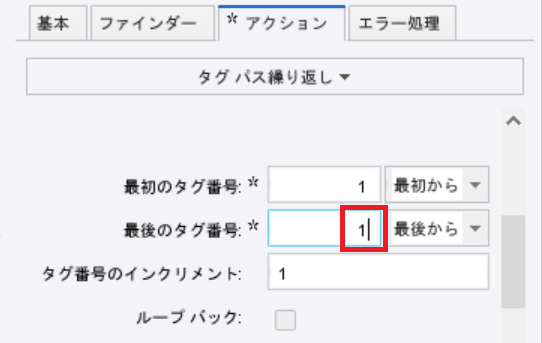
今回設定変更が必要なのは下のキャプチャの赤枠の部分の「最初のタグ番号」、「最後のタグ番号」です。
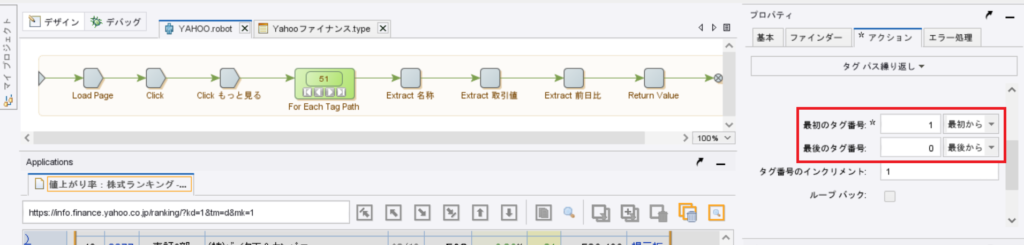
さて、「最初のタグ番号」の部分にはすでに「1」が入っています。
ピンときた方もいらっしゃるかもしれませんが、ループのステップを作る際に「最初の行を除外」という選択をしていることが、すでに「1」が入っていることにつながっています。
つまり、「2」を入力すると3行目からループが始まることを意味しています。
また今回は最後の行であるフッターを読まないようにしたいので、「最後のタグ番号」のところに「1」を入れることで最後の行を読まなくなります。
デバッグで再確認する
今回の記事の流れで、どのようなエラーが発生していて、どのステップが問題になっていて、どうすればエラーが解決できるのかを考えて対処してきました。
恐らく、これでエラーの対処が出来たはずですので、改めてデバッグをクリックします。
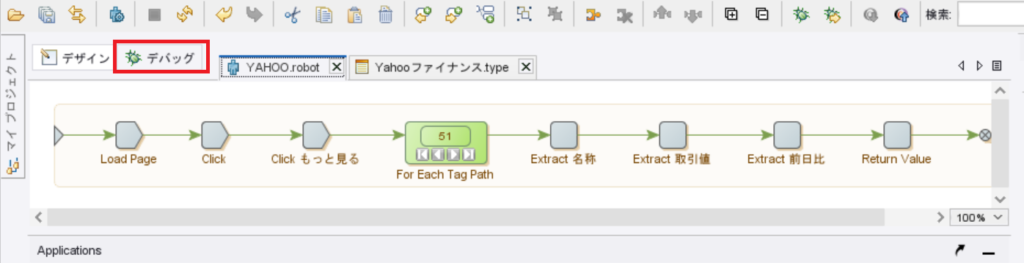
そして「▶」を押してロボットを実行させます。
するとエラーが発生せずに、左下に「実行は正常に完了しました。」と出てきました。
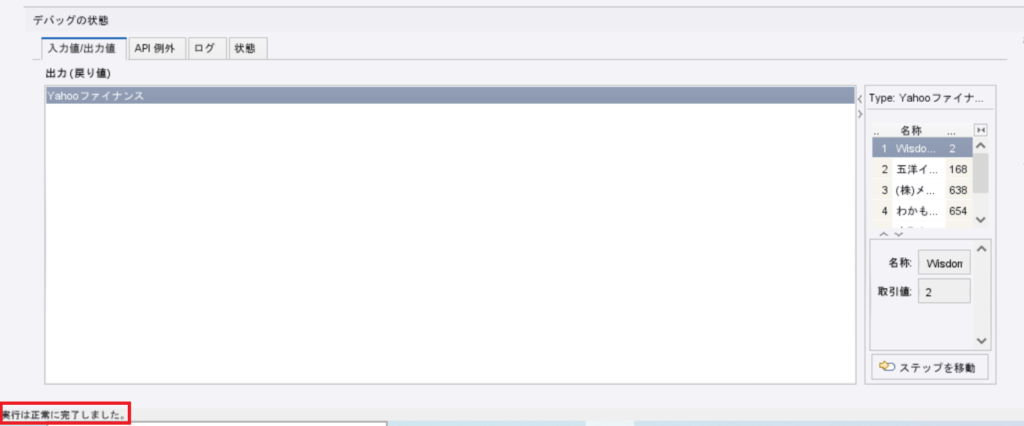
この状態になれば、エラーが出ずにロボットが指示通り完了したことが確認できたということです!

次回予告
次はページを移ってさらに多くの株価を抽出できるように設定をします。
今回株価を抽出したページは47ページある内の1ページ分だけを抽出しました。
なので、次回は47ページ分すべての情報を抽出できるようにロボットを作りこみます。
これだけの量を人が情報収集しようと思うとかなりの時間がかかってしまうと思いますので、BizRobo!の強みをより感じていただけるはずです!
お楽しみに!!

